| Open Source Sparse Tensor Computation Is Fast |
| Written by Mike James | |||
| Wednesday, 01 November 2017 | |||
|
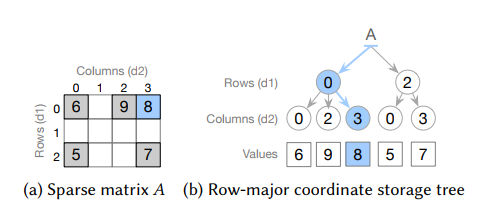
Tensors are data tables in n dimensions and when they occur they are often sparse, i.e. most of the entries are zero. In the past we have hand-crafted code to work efficiently with sparse tensors, but now we have Taco, an open source compiler that can automatically generate code that can run up to 100 times faster. A tensor is a matrix in more than two dimensions. A cube of data is a rank 3 tensor, and so on. The big problem with tensors is that they are often big and there just isn't enough storage to hold them. However, many tensors are sparse - mostly empty. For example, Amazon's customers mapped to products bought is a very large table with a lot of zeros. Most of us have encountered sparse matrices, if only on programming courses, and they are a standard part of studying data structures. The trick to working with them is to implement a storage scheme that stores the indices of only the elements that have data and then to work out how best to access the data to produce a fast algorithm. Researchers from MIT, the French Alternative Energies and Atomic Energy Commission, and Adobe Research have analysed the problem and implemented a compiler for sparse tensor manipulation. The system, called Taco - The Tensor Algebra Compiler, is open source and can be used as a C++ library and can generate C kernels that do specific operations. Usually when you do sparse tensor computation it tends to be broken down into its components. For example, AB+C is generally implemented by using code that multiples A and B and then code that adds C to the result. Behind the scenes this involves iterating through the sparse structures more than once. To be more efficient, Taco generates a set of iterations through the sparse structures that performs AB+C in one pass - this is the kernel of the operation. Here is an example of a rank 3 tensor multiplied by a one-dimensional vector using the Taco C++ library.
Notice that each tensor declared at the start can have separate dense and sparse dimensions and Taco takes this into account when it generates the iterations though each dimension.
Another optimization is that Taco automatically uses an indexing scheme to store only the nonzero values. For example, Amazon's table which maps customer ID numbers against purchases and terms from reviews takes 107 exabytes of data. Taco represents the same tensor in just 13 gigabytes. For a surprisingly detailed look at Taco see the official video:
You can get the Taco source code under an MIT license from its web site.
More InformationRelated ArticlesBreakthrough! Faster Matrix Multiply Covariance And Contravariance - A Simple Guide
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin.

Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Wednesday, 01 November 2017 ) |