| Sequential Storage |
| Written by Mike James | ||||||
| Thursday, 19 December 2019 | ||||||
Page 2 of 2
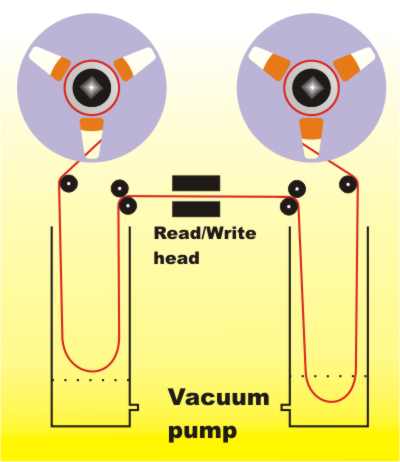
This all makes it sound as if digital tape drives were something very easy to build. If there is a minor problem with an audio tape the listener’s ear probably doesn’t even notice it and a even a big problem is only a plop or reduction in volume. For a digital tape drive even a small problem would result in the loss of a vital piece of data or part of a program. In addition the tape has to be able to be moved as quickly as possible past the read/write heads. Vacuum drivesMany ingenious solutions were thought up, but the one that became the standard was the “vacuum” drive. This isolated the heavy reels of tape from the small section of tape that was passing under the head by keeping a loop of tape “sucked” down into a chamber on each side. A servo mechanism caused the reels to turn, to supply more tape or take up slack, to keep the vacuum chambers full to the correct level. With such a mechanism a tape drive was able to move the tape past the head at 50m/s – once the tape was actually moving.
Tape drives really do suck! Two vacuum chambers pull tape from the reels to take the strain off the capstan wheels If you still think that a real computer isn’t a real computer without a “rocking” tape drive it might be worth pointing out the performance of these monsters! A typical reel of tape held from 2400 to 3600 ft of tape. A typical recording density was 800 bytes per inch so a complete tape, 18 inches or more in diameter and over half an inch thick, could store just 32MBytes! Even this pitifully small amount of storage is an upper estimate because in practice the tape would be started and stopped and this would leave gaps between the blocks of useful data so reducing the useful storage to 20MBytes or less. As to transfer rates, these were just as bad. The best that could be hoped for was 250KBytes/s, which puts it in the same league as a floppy disk or a single speed CD-ROM. Once again the time to start and stop, anything up to 10ms, would reduce this theoretical data rate to something much lower. Sequential files - Merge SortWe may not longer use sequential storage devices but we still use storage as if it was sequential. For example, the sequential file is a useful data structure that is the software embodiment of a tape drive. When data is written to a sequential file it is organized into fixed sized records. Each record is made up of a number of fields. In a modern computer the files generally aren't stored on tape but on a fast disk or even in primary memory. Today the idea of a sequential file is more the logical embodiment of a sequential storage device than anything physical. You can think of this as the software equivalent of a set of name and address cards. A write operation always writes a complete record to the file. In tape terms this corresponded to starting the tape moving, waiting until it is up to speed, then writing a block of data and stopping the tape. Reading also works in terms of records – a whole record is read even if only a single item of data is required. This behaviour is sometimes referred to as “block transfer” and tape drives and other similar device are often referred to as “block sequential”. After a little while tape drive use became a little more sophisticated and to save the space and time involved in starting and stopping it was usual to “block” records together so that more than one was written and read at one go – the so called “blocking factor”. Additional primary memory is set aside as a buffer to hold an entire block and the software only works in terms of a single record at a time, however now a real read or write operation only occurs when a buffer is empty or full. This is a technique that is still in use to speed data transfers today when disk drives are used. Although in principle it was possible to wind a tape to a particular point to find or write a particular record this was so time consuming that it generally wasn’t part of any sensible tape-based algorithm. Computer languages often had a “backspace” command but the most effective method of working with tape was to read or write till the point you had finished and then issue a “Rewind” command. Whole classes of now rarely used algorithms were invented to make tape-based data processing possible. In general these relied on a single computer having a multiple set of tape drives and used the principle of making copies of the source data while processing it. For example, the most difficult of all data processing tasks is sorting. In general to sort a list of values into order you have to move things around a lot and not in a way that suits a sequential file. However consider a slightly simpler problem – that of merging two already sorted lists. This is easy and you can do it using just three tape drives with list 1 on drive 1, list 2 on drive 2 and the output written to drive 3. The algorithm is:
When you have finished you have a completely sorted list on tape drive 3, and all by reading tape 1 and tape 2 sequentially. This leaves the problem of how you get two sorted lists in the first place? There are many ways of doing this. One is to first split the file into chunks small enough to fit into primary memory read them in and sort them. These can be written alternately to two separate tape drives and then the merge algorithm can be applied to these sorted chunks to produce chunks twice as big. As these new chunks are produced they are written alternately to two drives to be ready for another merge. This process continues at each step reducing the number of blocks by two and increasing the size of the blocks by the same factor. Beautiful isn’t it and yet the day of the merge sort has well and truly passed - or has it? The very latest sorting algorithm at use in major languages such as Python is called Timsort and it is a blend of merge sort and insertion sort. Of course in this case no tapes are involved the merging is done in fast primary memory but it is still a merge sort. To find out more about merge sort see: Magic of Merging.
What Programmers Know
Contents
* Recently revised
Comments
or email your comment to: comments@i-programmer.info To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Facebook or Linkedin. 
<ASIN:1862078394> <ASIN:1403315175> |
||||||
| Last Updated ( Friday, 27 December 2019 ) |